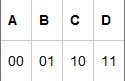
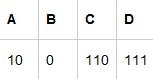
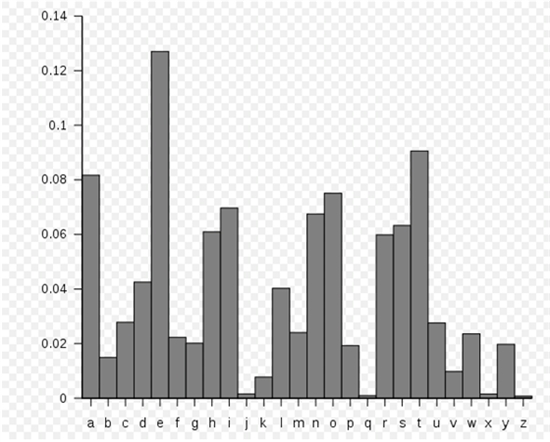
数据是怎么被压缩的 |
| |
相关帖子你静静地居住在我的心里,如同满月居于夜空!
|
|
| |
|
互相尊重,互相理解,共同提高
|
|
| |
|
Nothing can stop us!
|
|
| |
|
|
|
| |
|
一只爱天文的伪Geek
|
|
APP下載|手机版|爱牧夫天文淘宝店|牧夫天文网 ( 公安备案号21021102000967 )|网站地图|辽ICP备19018387号
GMT+8, 2026-7-26 22:46 , Processed in 0.068835 second(s), 6 queries , Gzip On, Redis On.





 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡